别再让素材在库里失踪。现在就能一秒找到。
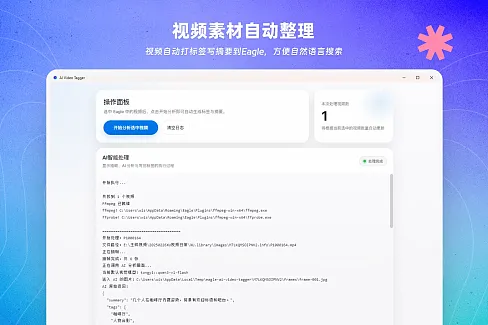
AI Autotagger 使用视觉语言模型分析你的图片和视频(OpenAI、Anthropic、Google、OpenRouter,或本地方案如 Ollama 和 LM Studio),并按你定义的规则把标签、名称和描述写回 Eagle。设计师、摄影师和研究人员每月处理超过1,000万个项目,他们早就受够了手动打标签。
为什么选择 AI Autotagger?
大多数自动打标签工具都是黑盒。它们猜你想要什么标签,却不给你任何自定义输出的方式。最后你只会得到一堆像 “photo” 或 “design” 这样的通用标签,完全不符合你真正理解和整理素材的方式。
AI Autotagger 不一样。你可以创建带有明确规则的 预设:生成哪些标签、要不要重命名、写什么描述、以及 AI 应该如何解读你的内容。摄影、UI 设计、时尚、OCR、产品图都能用同一套引擎处理,因为指令由你来定。
想让 AI 识别光线条件和拍摄角度?加一条规则就行。需要它提取品牌 Logo 并按公司归类?把这条指令写进去。这种灵活性让一个插件适配你在收集的任何东西,而不是把你塞进别人定义的分类体系。
关键功能
8 家 AI 提供商可选,也可本地免费运行模型
支持 OpenAI、Anthropic、Google Gemini 和 OpenRouter;也可以用 Ollama 和 LM Studio 在本地免费运行,离线、私密。你还可以使用 Claude Code CLI 或 Codex CLI,这样能用现有订阅,而不是按每次 API 调用付费。
支持自定义模型名称,所以新模型一发布你当天就能用,无需等待插件更新。
你定义想要的标签,而不是让 AI 猜
精确控制生成哪些元数据:
- 标签:与现有标签合并,或完全替换。可提供示例标签(AI 会按你的风格生成),或给出固定列表(AI 只能从你的选项里选)。还能加前缀/后缀,把相关标签分组。
- 名称:按内容重命名项目。把 `IMG_20240115_143052.jpg` 清理成更可搜索的 `sunset-beach-golden-hour`。
- 描述:详细描述、OCR 文本提取或自定义分析。你可以让 AI 写一句话摘要、详细拆解,或提取所有可见文字。
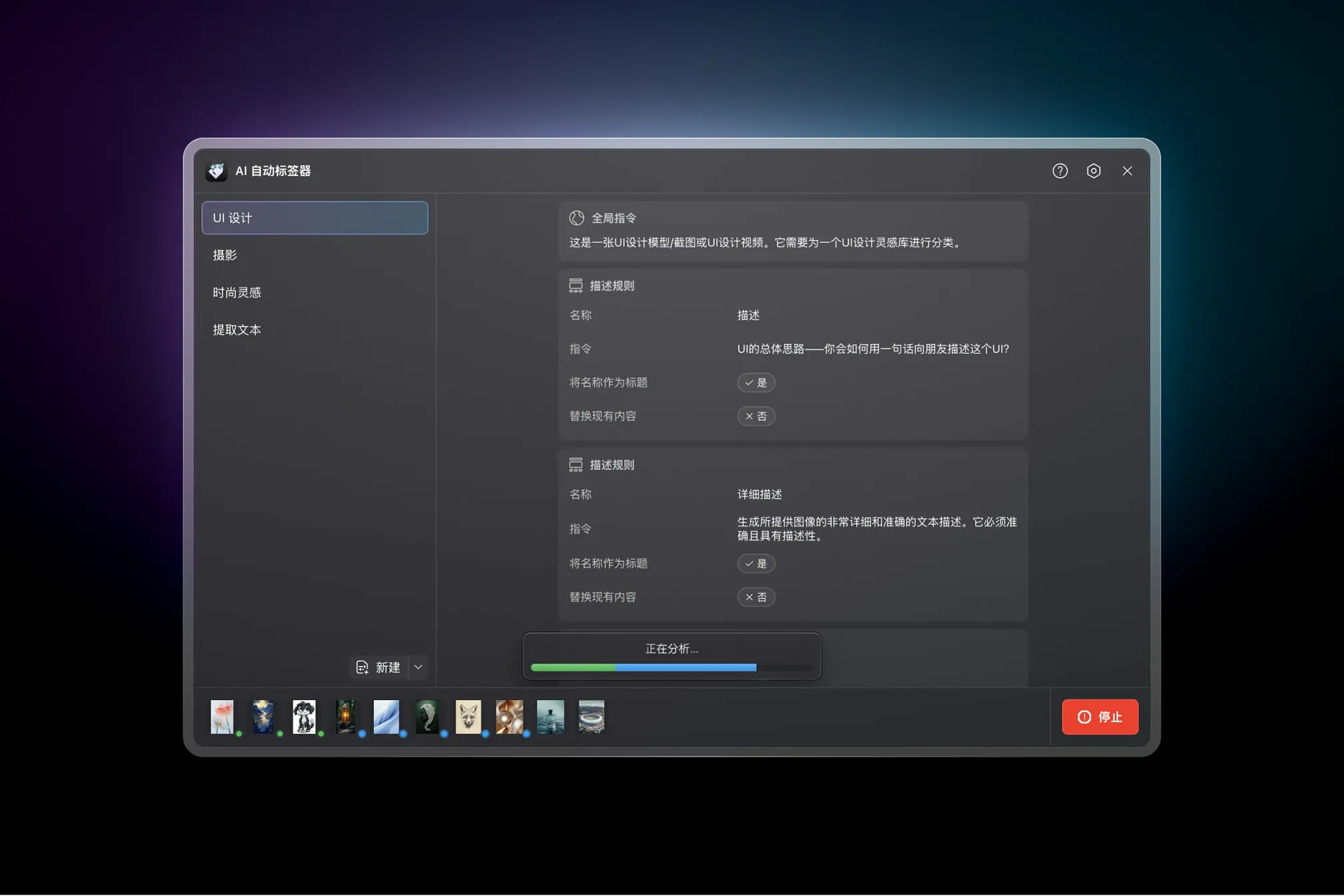
规则按 预设 分组。预设可瞬间切换以处理不同内容类型:先用「摄影」预设跑相机导入,再切到「UI 设计」预设处理截图收藏。
6 个内置预设,几秒上手
开箱即用,立即开始分析:
- 摄影:识别题材、光线条件、配色、氛围和摄影类型。推荐相似艺术家,并记录时间段或季节。
- UI 设计:识别界面组件(按钮、卡片、模态框)和更高层模式(仪表盘、登录表单、定价表)、设备类型、配色方案与字体风格。提取可见文字以便搜索。
- 时尚灵感:对服装归类,识别风格(街头、高定、运动休闲),记录配色、图案与材质纹理。检测年代影响与场景语境。
- 提取文本:从截图、扫描文档和图片中提取所有可见文字,尽量保留层级与格式。
- 重命名项目:基于内容生成描述性文件名,同时保留原始名称中的关键信息。
- 自定义:从零开始,按需搭建。
每个预设都可完全编辑。用默认配置做起点,再把规则改成符合你工作流的样子。
用自然语言描述预设,AI 帮你生成
不知道怎么组织预设?用自然语言描述你想要的结果,AI 会替你写出预设。
例如:“创建一个用于归类产品照片的预设。我需要产品类型、主色和材质的标签,并生成一个简短的描述性文件名。”
生成器会输出一个完整预设,包含合适的规则、示例标签和指令。你可以微调,也可以直接使用。
预设放进文件夹,随时备份与恢复
让预设管理更清爽:
- 文件夹:拖拽预设到文件夹,按工作流分组
- 复制:克隆预设,用作变体的起点
- 导入/导出:用 JSON 分享预设,或备份你的配置
- 自动备份:插件保存快照,出问题可恢复到旧版本
认真分析视频,不只看缩略图
视频分析使用多个帧,而不是单张缩略图。插件会根据视频长度以可变采样率抽取帧:短片每秒抽取更多帧,长视频则在全时长内抽取具有代表性的样本(最多 60 帧)。
这意味着 AI 看到的是视频里真正发生的内容,而不是 Eagle 偶然选作缩略图的那一帧。
同一项目绝不重复处理
跳过规则可以避免对已处理项目重复分析。你可以配置一个跳过标签:当插件看到项目带有该标签,就会跳过不处理。也可以让插件在处理后自动加上跳过标签,这样每个项目只分析一次。
这让增量工作流变得可行:只分析新导入内容,不必反复重跑整个库。
实时知道你在花多少钱
Token 使用量和成本估算会随操作实时更新。成本小组件会显示当前会话的累计消耗,并按输入/输出 Token 拆分。
每个模型的单价都可配置,提供商改价时你可以修改数字,让估算保持准确。本地提供商(Ollama、LM Studio)会显示零成本,因为它们跑在你的硬件上。
API key 本地加密,凭证只属于你
API key 会在保存前用你设置的密码加密。密码本身不会被保存,开始分析会话时会提示你解锁。
如果忘记密码,你可以重置并重新输入 key。加密意味着即使有人拿到你机器的存储,也无法在没有密码的情况下读取你的 key。
边工作边跑完整库
可配置并发,一次给几百个项目打标签。选中要分析的内容,点一下按钮,实时看进度。
并发可从保守(一次 1 个请求)到激进(100 个并行请求)。并发越高越快,但可能会因提供商不同而触发限流。需要停下时随时取消。已完成的会保留,你之后可以继续处理剩余项目。
提供 8 种语言
完整界面本地化:英语、德语、西班牙语、日语、韩语、俄语、简体中文、繁体中文。插件会自动识别 Eagle 的语言设置。
工作方式
- 在 Eagle 中 选择项目(想选多少都行)
- 从插件工具栏 打开 AI Autotagger
- 选择一个预设(或创建一个符合需求的预设)
- 点击 `运行分析` 并确认你正在使用的模型
- 看标签、名称和描述 实时写入
就这么简单。插件会处理图片缩放(可配置分辨率以平衡质量与成本)、带自动重试的 API 调用,以及把元数据写回 Eagle。你还可以按状态过滤列表,查看哪些已完成、哪些处理中、哪些失败。
自带密钥(Bring Your Own Key,BYOK)
AI Autotagger 采用 “Bring Your Own Key” 模式。你在 OpenAI、Anthropic、Google 或 OpenRouter 创建账号,生成 API key 并粘贴到插件里。你直接向提供商按用量付费,没有中间加价,也没有订阅费。
想要完全免费、离线、私密使用:安装 Ollama 或 LM Studio,下载支持视觉的模型(如 LLaVA),然后把插件指向你的本地服务器。你的图片留在本机,持续成本只有电费。
大家用它做什么
- 设计师:你存了 3,000 张 UI 截图,想找那张带仪表盘指针图的?祝你好运。AI Autotagger 按组件、模式和配色打标签,所以搜索 `仪表盘 仪表图 深色模式`(`dashboard gauge chart dark mode`)真的能出结果。
- 摄影师:每次拍摄都会往库里加几百张图。手动一张张打标签?那是好几个小时。让 AI 在你修图时处理题材、光线、氛围和类型标签。
- 研究人员:扫描文档、PDF 截图、文章剪贴,不 OCR 就不可搜索。「提取文本」预设会提取每一个字,让你的纸质归档也能检索。
- 内容创作者:下载文件夹里全是 `screenshot-2024-01-15.png` 和 `IMG_4829.jpg`。「重命名项目」预设会把它们变成 `twitter-thread-design-systems-dark-mode.png`,半年后你也找得到。
- 时尚档案整理者:按风格、年代、品牌、配色和质感给服装归类。建立一个参考库,让 “1970s bohemian floral maxi dress” 返回的就是你期待的结果。
开始使用
- 在 Eagle 中 安装插件(偏好设置 → 插件 → 添加插件)
- 打开 `设置` 并选择提供商
- 添加你的 API key(或为 Ollama/LM Studio 配置本地服务器 URL)
- 选择一些项目 并点击 `运行分析`
自定义 OpenAI 兼容提供商,可连接任何支持 OpenAI 格式的 API
AI 预设生成器现在支持 CLI 提供商(Claude Code、Codex)
应用内更新通知,重要公告会显示在更新对话框中
刷新大量项目选择时显示警告以防止卡顿
改进视频处理,ffmpeg 不可用时错误消息更清晰,超时时间根据视频时长自动调整
修复:特定位置拖放预设不再崩溃
修复:标签修饰符文本现在可以留空
修复:Ollama 自定义模型名称不再意外重置
- 新增 AI 驱动的预设生成器——用自然语言描述您的标签需求
- 新增预设备份与恢复工具——自动备份,并支持手动备份/恢复
- API 密钥以密码保护存储,支持解锁并迁移现有密钥
- 实验性支持 Claude Code CLI 和 Codex CLI 提供商——使用本地 CLI 工具替代 API 调用
- 新增 OpenRouter 提供商——通过统一 API 访问多个 AI 模型
- 按提供商提供高级设置:温度、最大令牌和思考预算
- 新增内置帮助对话框,包含文档与常见问题
- 新增预设文件夹,支持拖放排序——在侧边栏整理预设
- 可从“默认预设”子菜单在“新建”按钮下拉中添加单个默认预设
- 支持 Claude 4.5、GPT-5.x 和 Gemini 3.0 模型
- 支持简体中文、繁体中文、德语、日语、韩语、俄语和西班牙语
- 刷新或切换预设时实时更新项目状态
- 改进批量处理时的内存管理
- 多项 UI 修复
Fixed: LM Studio and Ollama base URLs couldn't be changed
Fixed: maxTokens error
Added option to process items using their thumbnail images (e.g., SVGs)
Added support for tag modifiers with configurable position and spacing
Improved processing for very large inputs/outputs (e.g., long documents)
Version 7 (Included in this release)
Added Ollama and LM Studio support for local model inference
Improved model selection UI, including allowing custom model names so you can now use the latest models as soon as they're released
Added option to resize items before AI processing (improves speed/cost)
Added Gemini Flash 8B model
Improved UI freezing issues when processing many items
Added detailed logs for each item
Fixed: Item names longer than 245 characters are now truncated to avoid data corruption
Added Ko-Fi button for those who want to support the project
Auto-refresh items when you change the selection in the main Eagle window
Copy and paste presets — share presets with people!
Option to send low-res versions of images/videos to reduce API cost
Improve reliability of Google's Gemini 1.5 models
Various bug fixes and UI improvements
Fix double-paste API key bug on Windows