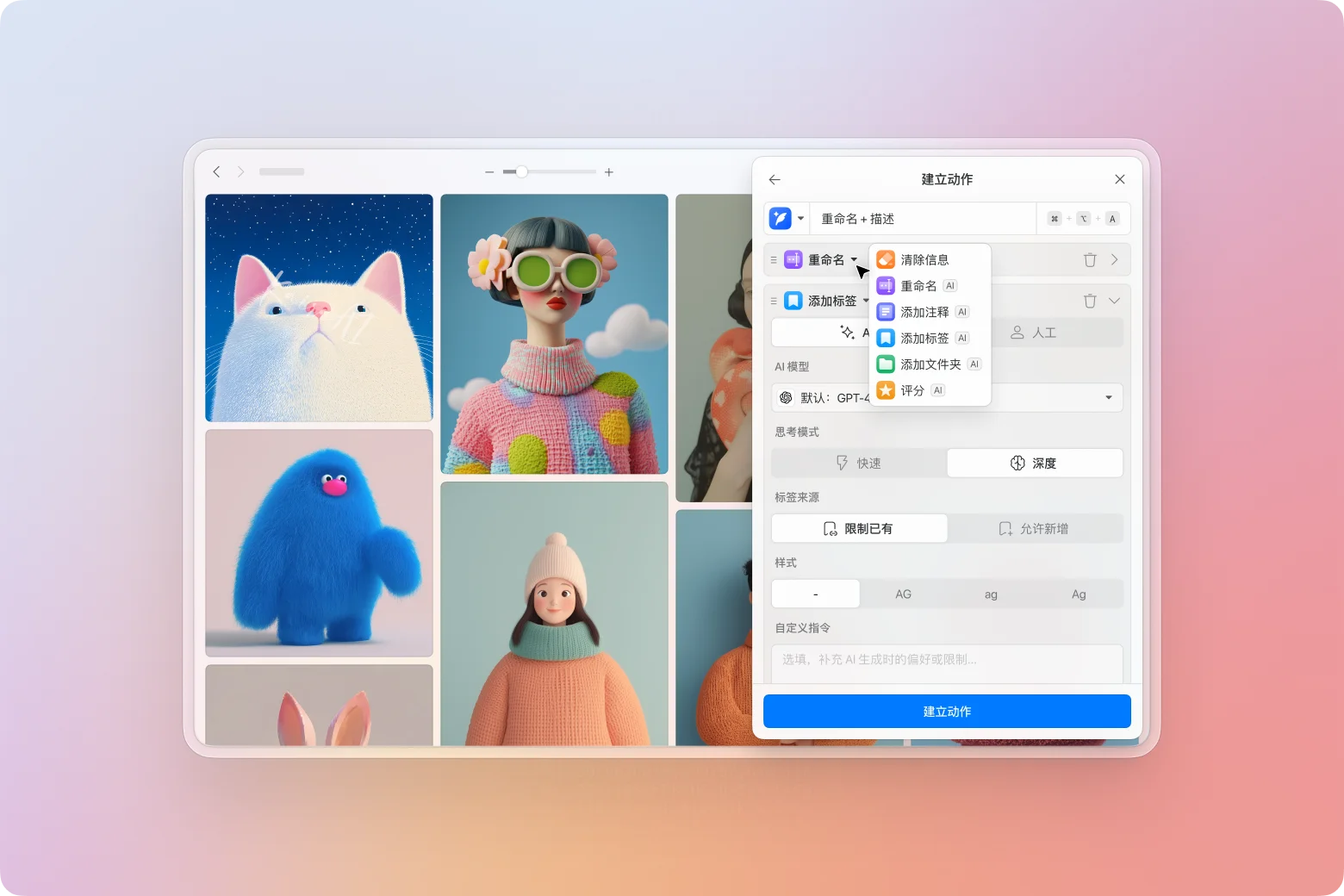
 AI 动作是一款可通过 AI 自由组合的图片批量处理工作流插件。你可以让 AI 自动为图片重命名、编写描述、添加标签、分类到文件夹,甚至进行评分,将原本繁琐的整理流程浓缩成一次执行。
AI 动作是一款可通过 AI 自由组合的图片批量处理工作流插件。你可以让 AI 自动为图片重命名、编写描述、添加标签、分类到文件夹,甚至进行评分,将原本繁琐的整理流程浓缩成一次执行。
接下来从安装开始,一步步创建并执行你的第一个 AI 动作。
开始前:先安装并配置 AI 模型套件
为什么需要 AI 模型套件?
AI 动作本身负责执行工作流,但图片分析的能力来自 AI 模型。 而 AI 模型套件就是 Eagle 统一的模型配置中心,只需要安装一次,之后所有 AI 插件都可以共用这套配置。先配置好 AI 模型套件,AI 动作 才能正常运行。
安装 AI 模型套件
打开 Eagle → “插件” → “插件中心” → 搜索 “AI 模型套件” → 点击安装。
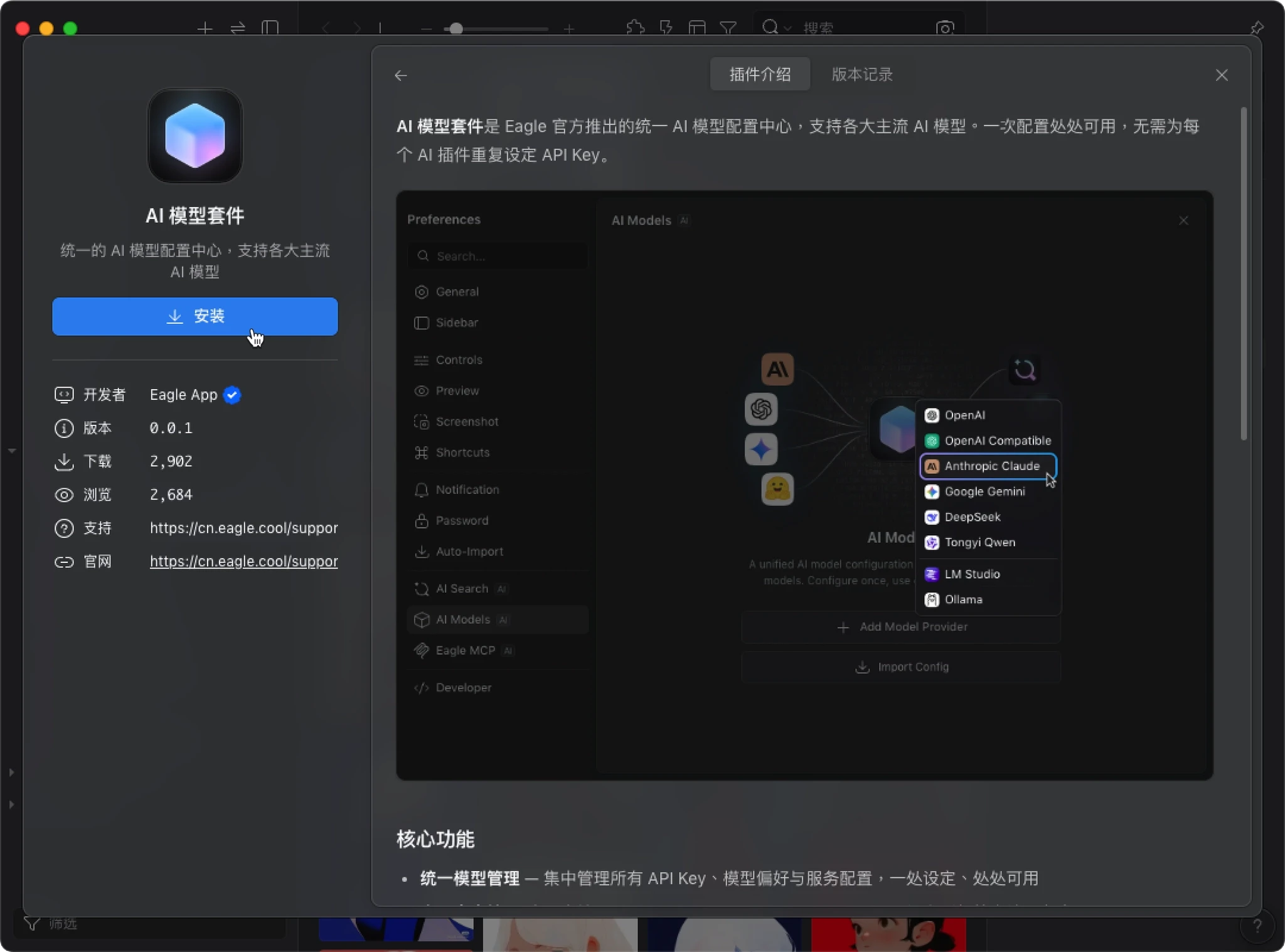
配置 AI 模型(以 Claude 为例)
- 安装完成后,打开 Eagle 的 “设置”
- 进入侧栏的 “AI 模型套件”
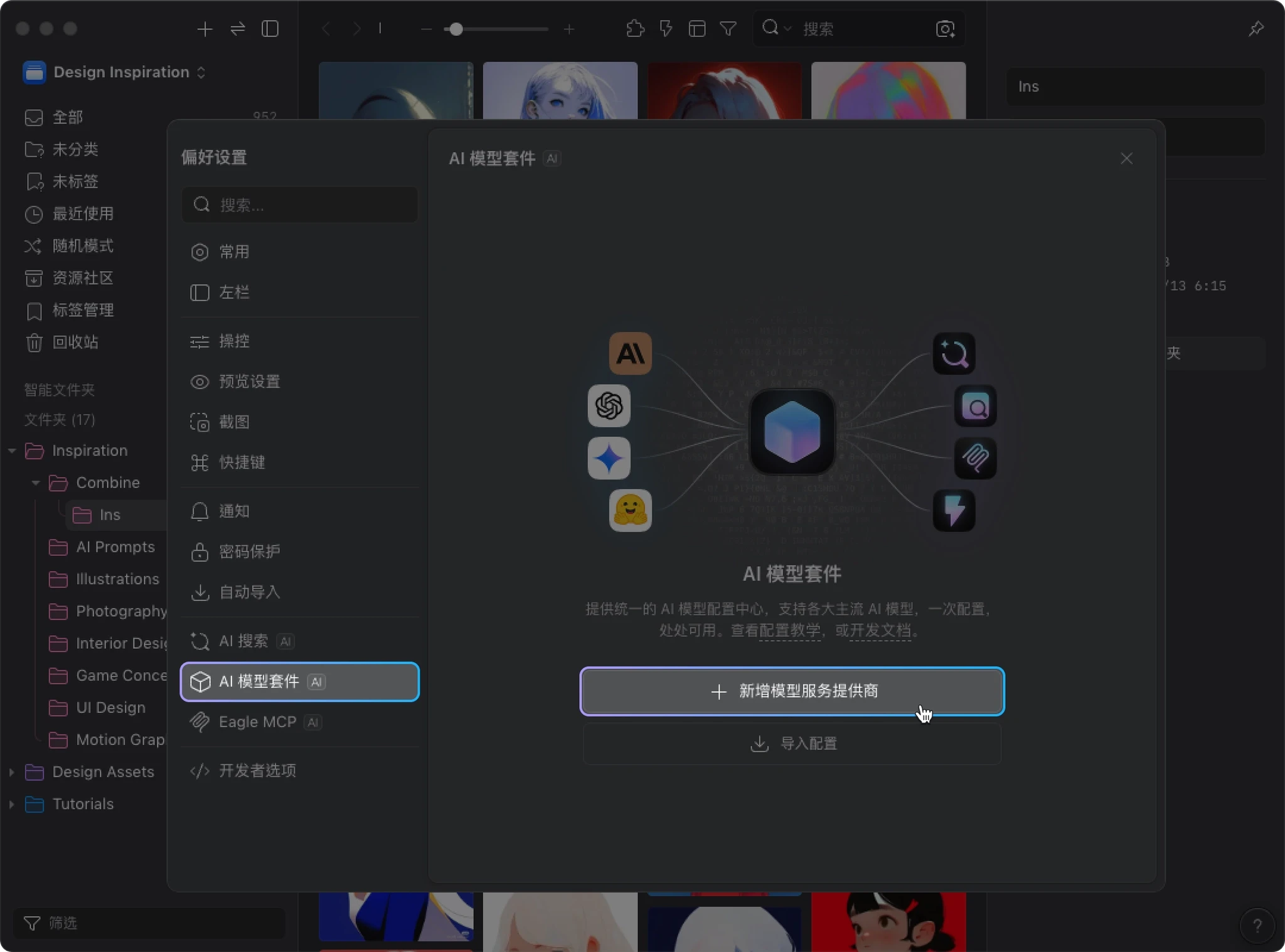
- 点击 “新增模型服务提供商”,选择你要使用的服务商(以下以 Claude 为例)
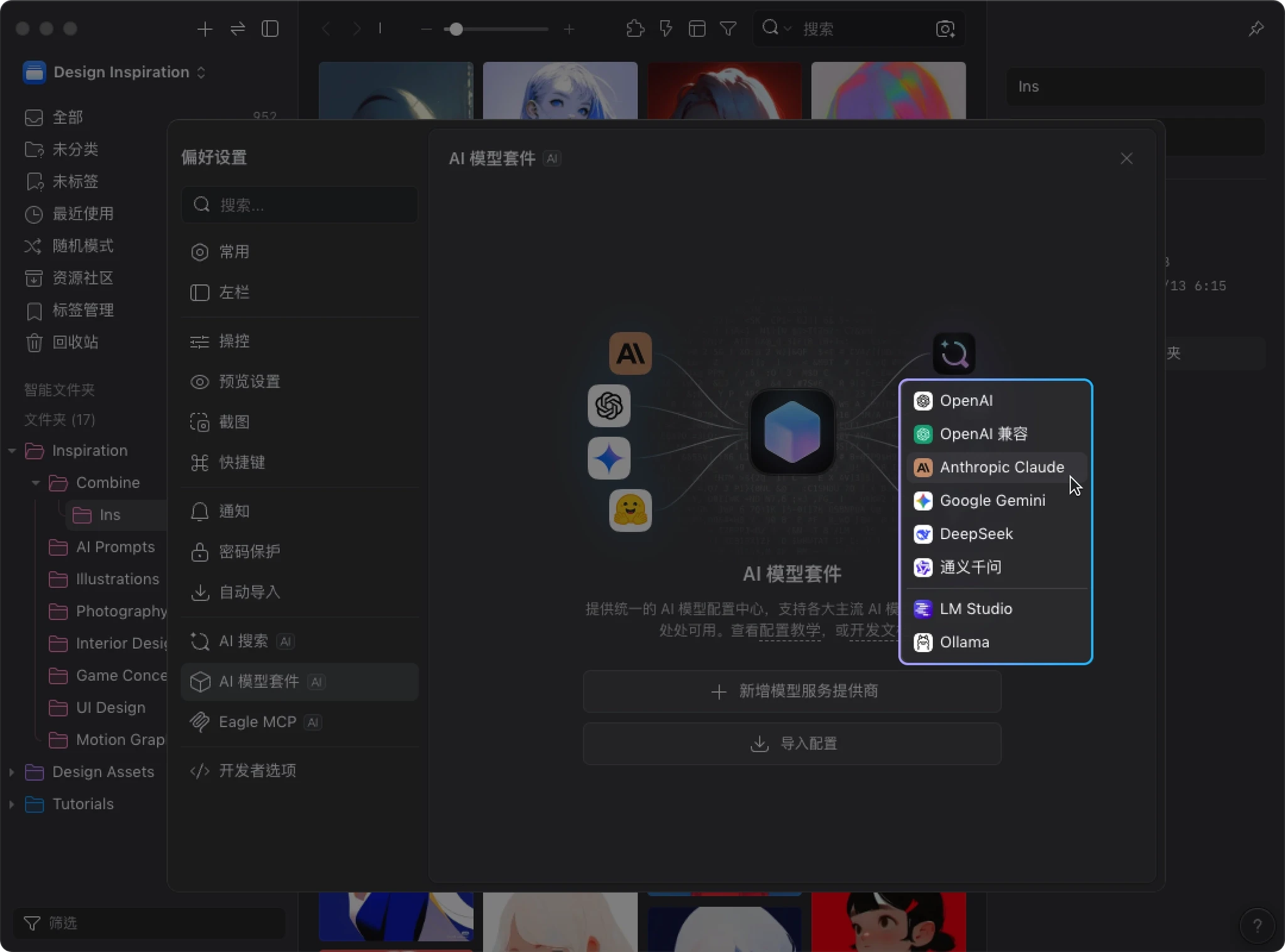
- 输入 API Key 后,点击 “创建”
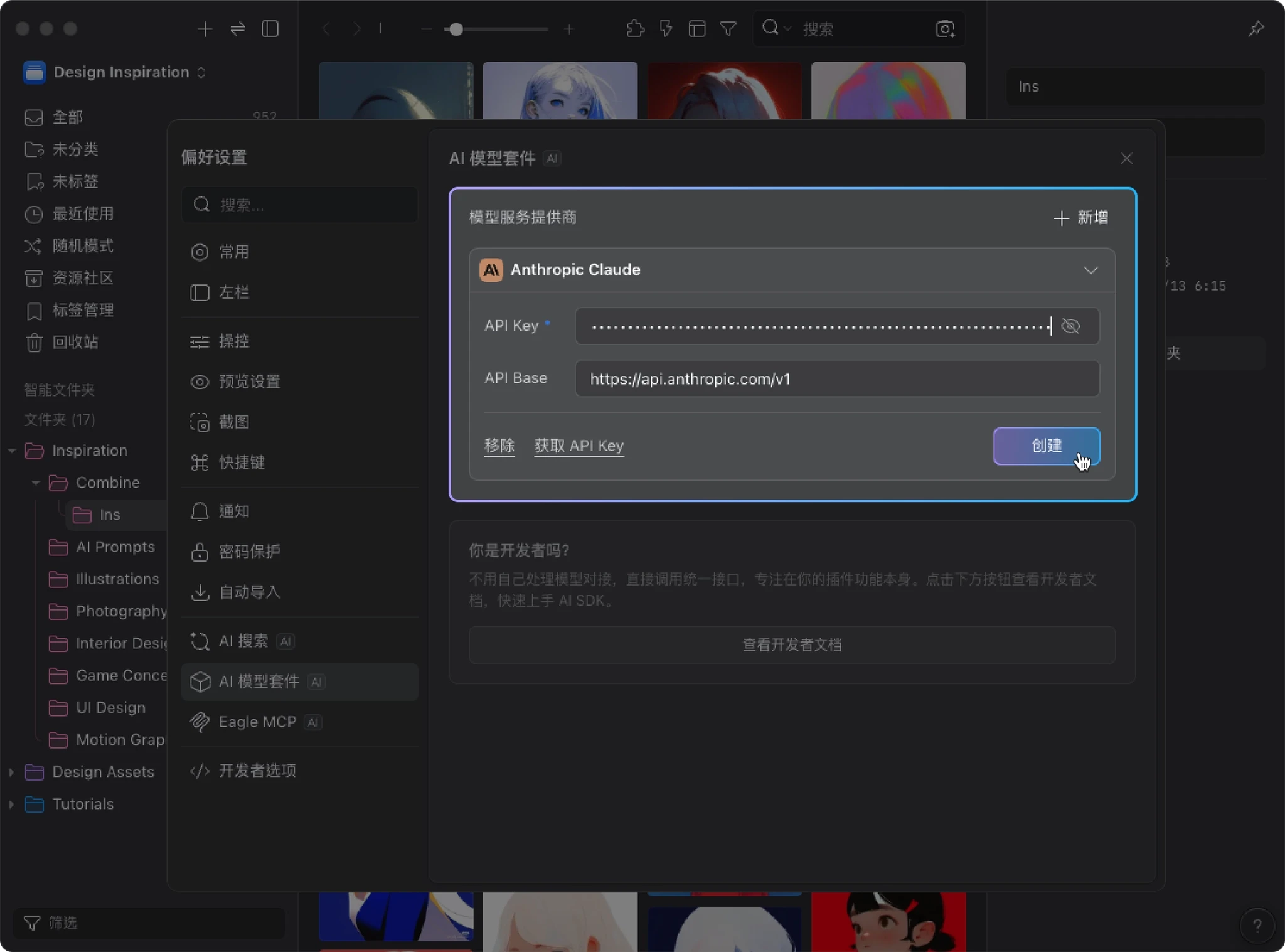
设置默认模型
完成 API Key 对接后,请务必确认 默认模型 中的 “视觉模型(Vision Model)” 已正确设置。
AI 动作需要“看懂”图片才能处理,所以必须设置视觉模型。没有设置的话,AI 动作 无法执行。
更完整的配置方式,请参考 AI 模型套件配置指南。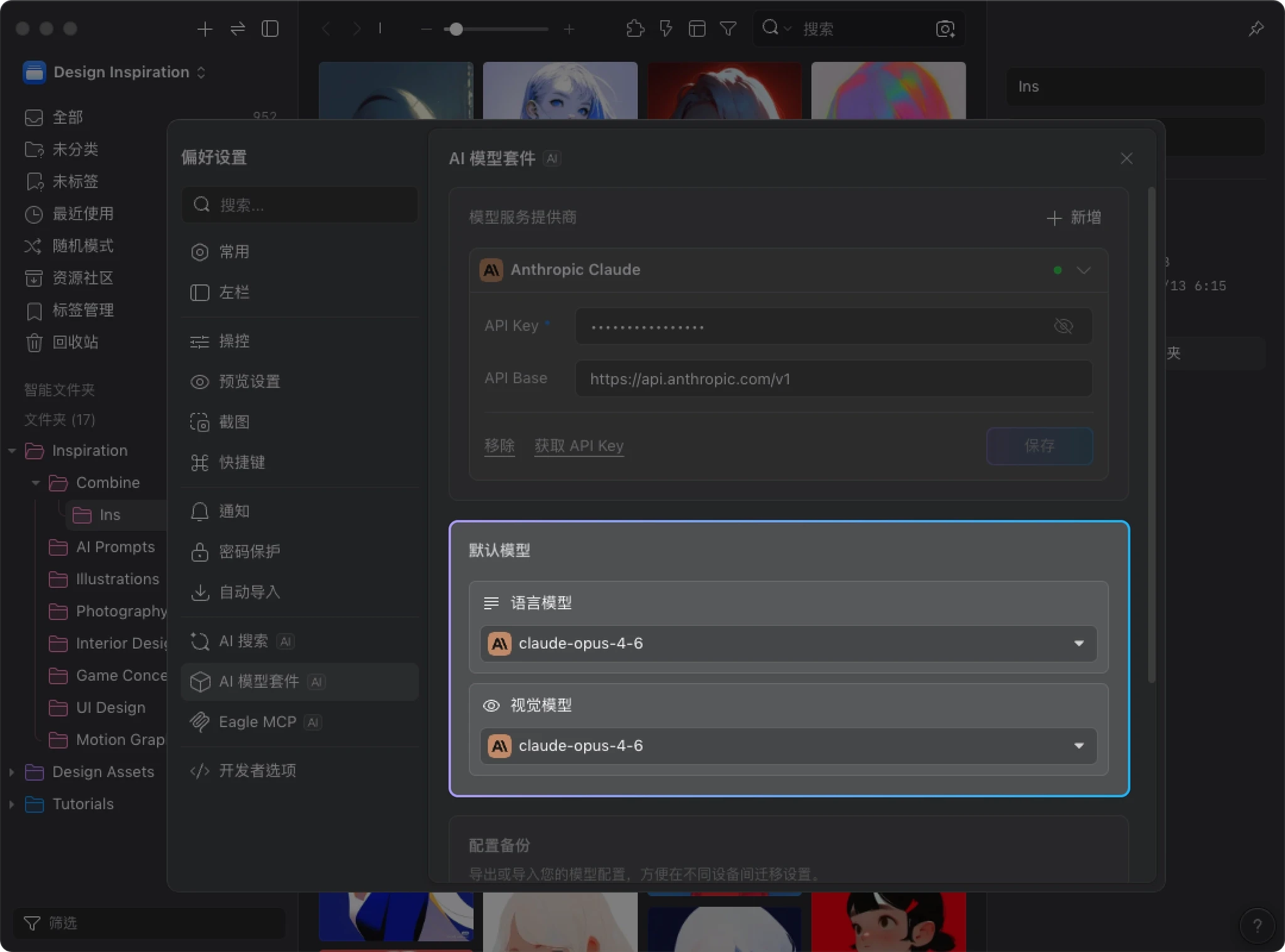
目前推荐使用 Claude 系列模型,可以根据需求选择:
| 使用场景 | 推荐模型 |
|---|---|
| 预算充足,追求最佳效果 | Claude Opus 4.6 |
| 平衡效果与成本 | Claude Sonnet 4.6 |
| 预算有限,轻量任务 | Claude Haiku 4.5 |
更习惯用国内模型?这里也有推荐
本文用 Claude 做示范,但如果你更习惯使用国内服务商,或者已经有现成的 API 账号,以下这些模型同样支持图片理解,可以直接用在 AI 动作 里。
由于不同模型的训练方式和擅长领域各有差异,实际效果不会和 Claude 完全一样,但在各自的定位上都是国内目前比较有代表性的选择。建议先小批量测试,找到适合自己任务的模型。
能力优先(对标 Opus 档位)
| 模型 | 提供商 |
|---|---|
| Qwen3.5-Plus | 阿里通义千问 |
| Kimi K2.5 | 月之暗面 |
| GLM-4.5V | 智谱清言 |
| Doubao-Seed-1.8 | 字节豆包 |
价格 / 速度优先(对标 Haiku 档位)
| 模型 | 提供商 |
|---|---|
| Qwen3.5-Flash | 阿里通义千问 |
| Qwen3-VL-Flash | 阿里通义千问 |
| Doubao-Seed-1.6-thinking | 字节豆包 |
| Qwen2.5-VL 系列(如 qwen-vl-plus) | 阿里通义千问(上一代,价格更低) |
使用本地模型(如 LM Studio)的最低要求
如果你希望通过 LM Studio 等工具在本地运行模型,而不是使用云端 API,请先确认设备是否符合以下条件。
硬件要求
运行大语言模型需要独立显卡(GPU),建议至少配备 12GB 以上的显存(VRAM)。
模型建议
不同任务对模型能力的要求不同:
| 使用场景 | 最低模型要求 | 建议模型 |
|---|---|---|
| AI 重命名、AI 描述 | Qwen3 4B | Qwen3 8B |
| AI 打标签、AI 文件夹(自动分类) | Qwen3 8B | 更大的模型 |
AI 重命名 / AI 描述 这两类任务相对简单,Qwen3 4B 通常已可使用;如果想提升稳定性与质量,建议使用 8B 版本。
AI 打标签 / AI 文件夹 这类任务通常涉及更复杂的理解、判断与分类逻辑,因此至少需要 Qwen3 8B 以上 的模型。
本地模型 vs 在线模型
如果你的设备资源有限,通常更建议使用在线模型(例如 Claude、OpenAI 等):
在线模型通常比本地运行快不少,商业 API 模型在效果上也优于多数本地模型。此外,在线模型不占用本机资源,长时间批量处理时更稳定。
安装 AI 动作 插件
- 打开 Eagle → “插件” → “插件中心” → 搜索 “AI 动作” → 点击安装。
- 安装完成后,打开 “插件” → “AI 动作”。
- 第一次打开时,你可以点击 “了解详情” 查看功能介绍。窗口底部会看到三个入口:
- “创建动作”:从零开始创建新的动作
- “从模板创建”:从预设模板快速创建
- “导入动作”:导入其他人分享的动作
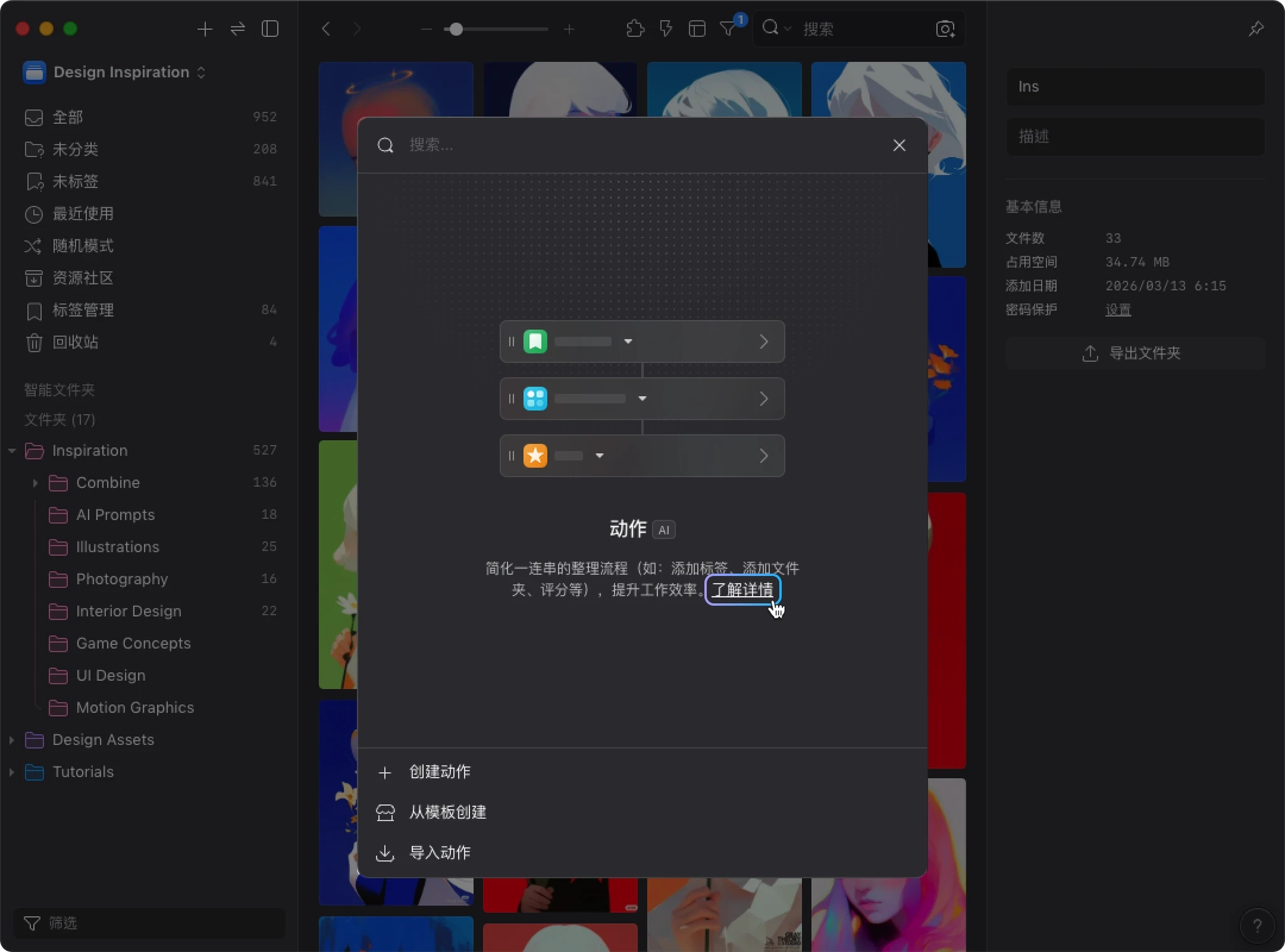
创建你的第一个 AI 动作
这里我们先从最简单、也最容易看出效果的例子开始:AI 重命名。
1. 创建动作
- 点击 “创建动作”
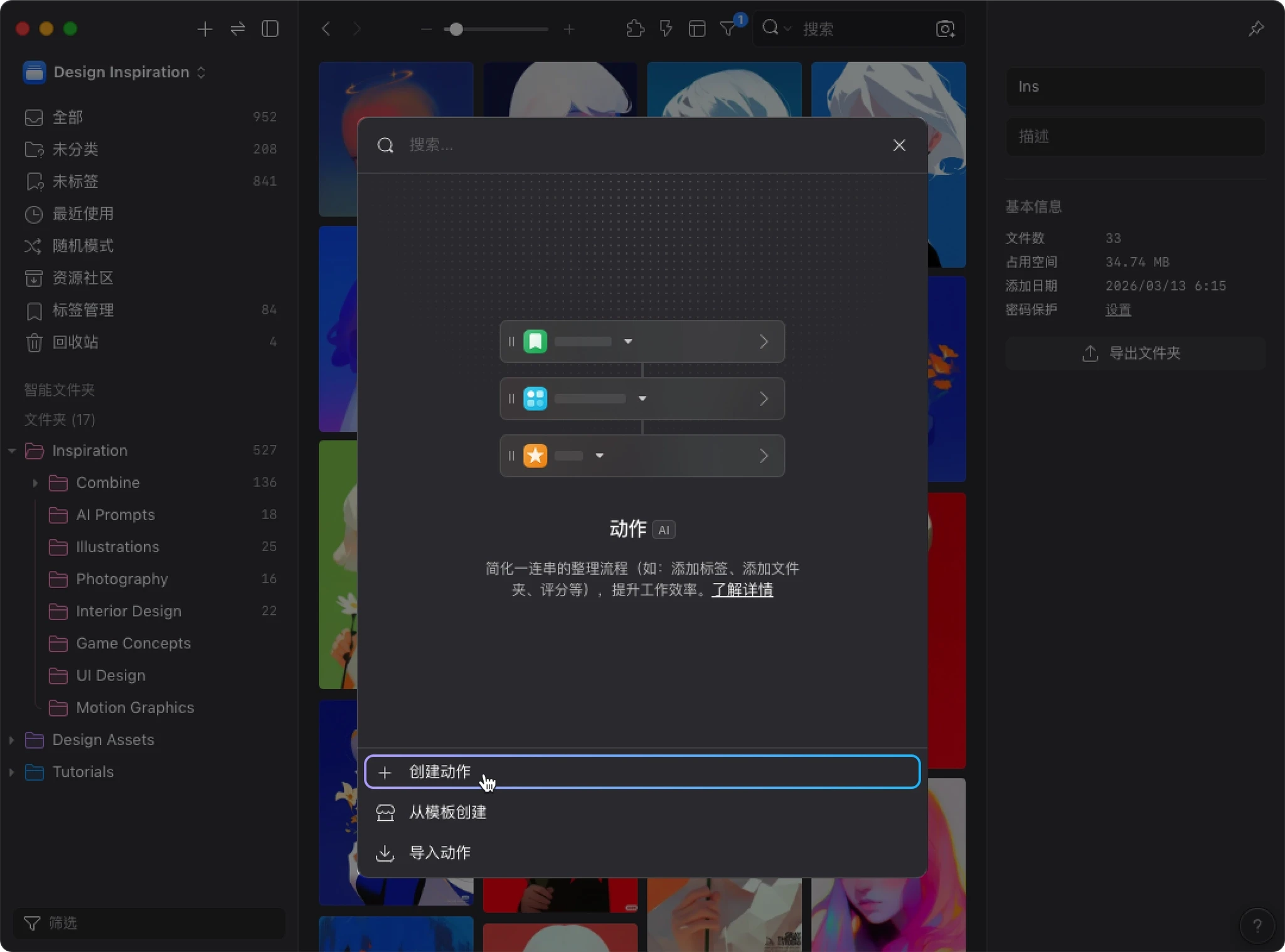
- 进入创建界面后,先选择一个代表图标
- 在 “名称” 字段输入动作名称,例如:AI 重命名
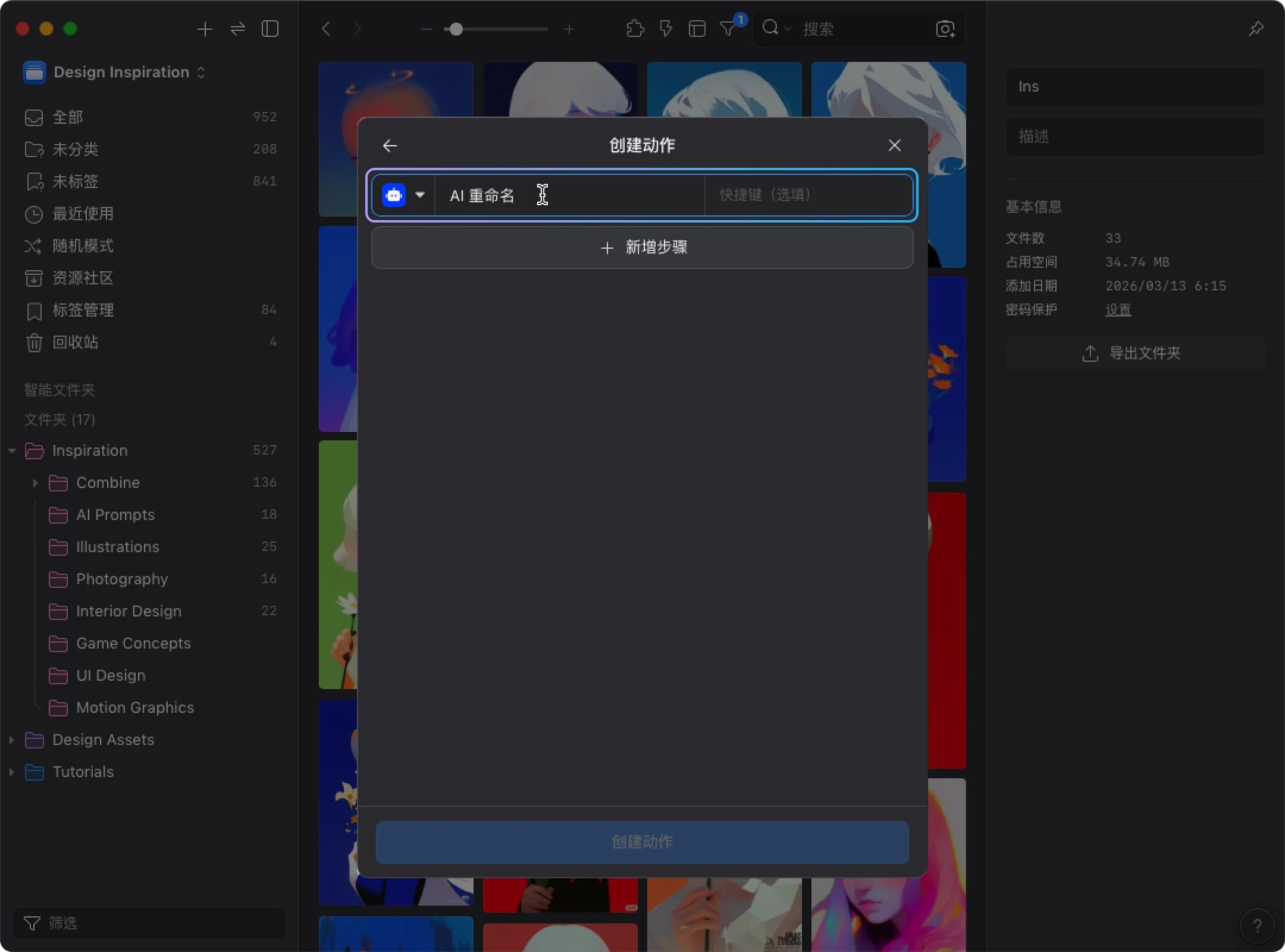
- 根据需求设置快捷键(选填)
2. 添加步骤
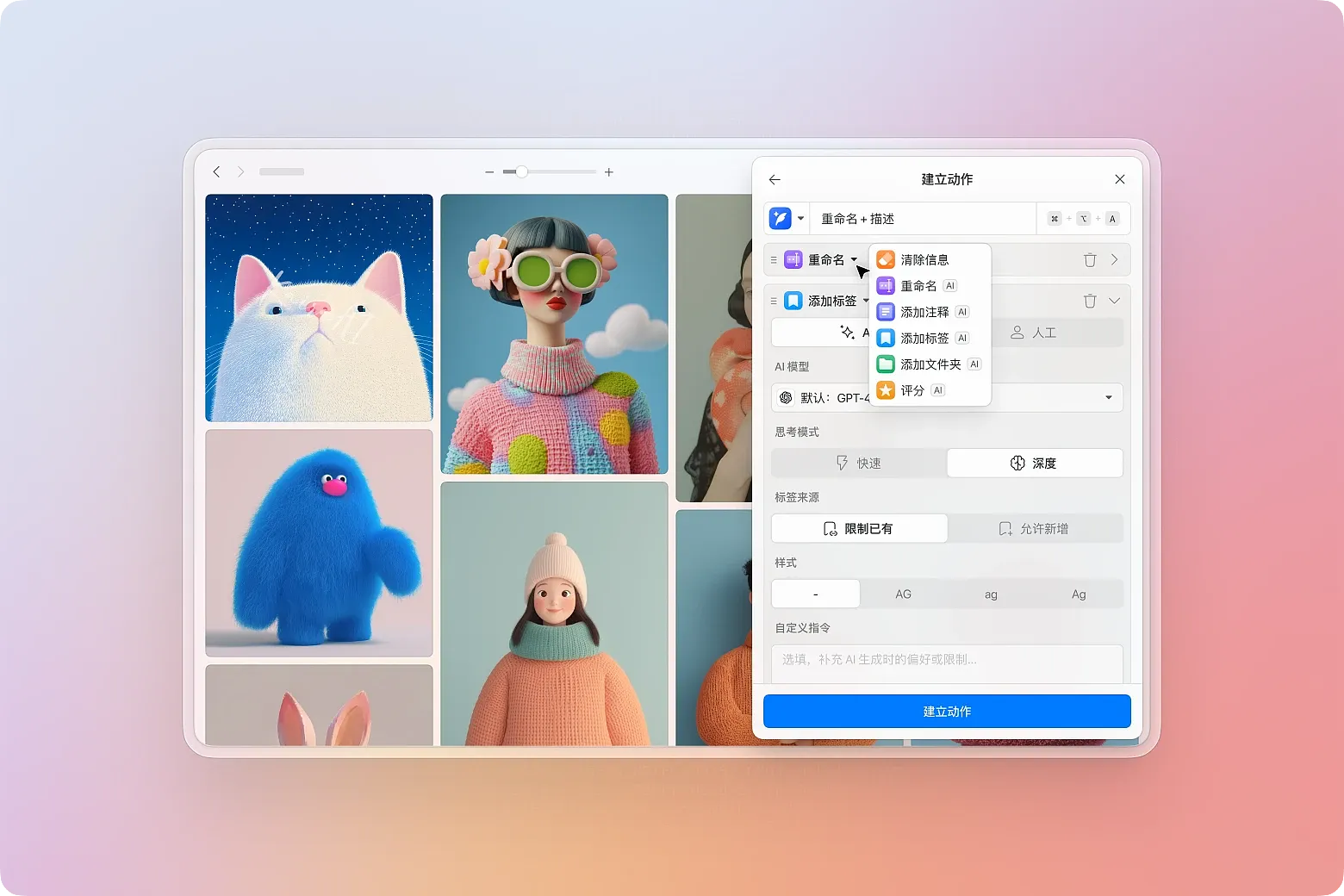
点击 “+ 新增步骤” 后,你会看到所有可用的操作类型:
- 清除信息:清除描述、链接、标签、文件夹或评分等字段
- 重命名
- 添加注释
- 添加标签
- 添加文件夹
- 评分
这次请选择 “重命名”。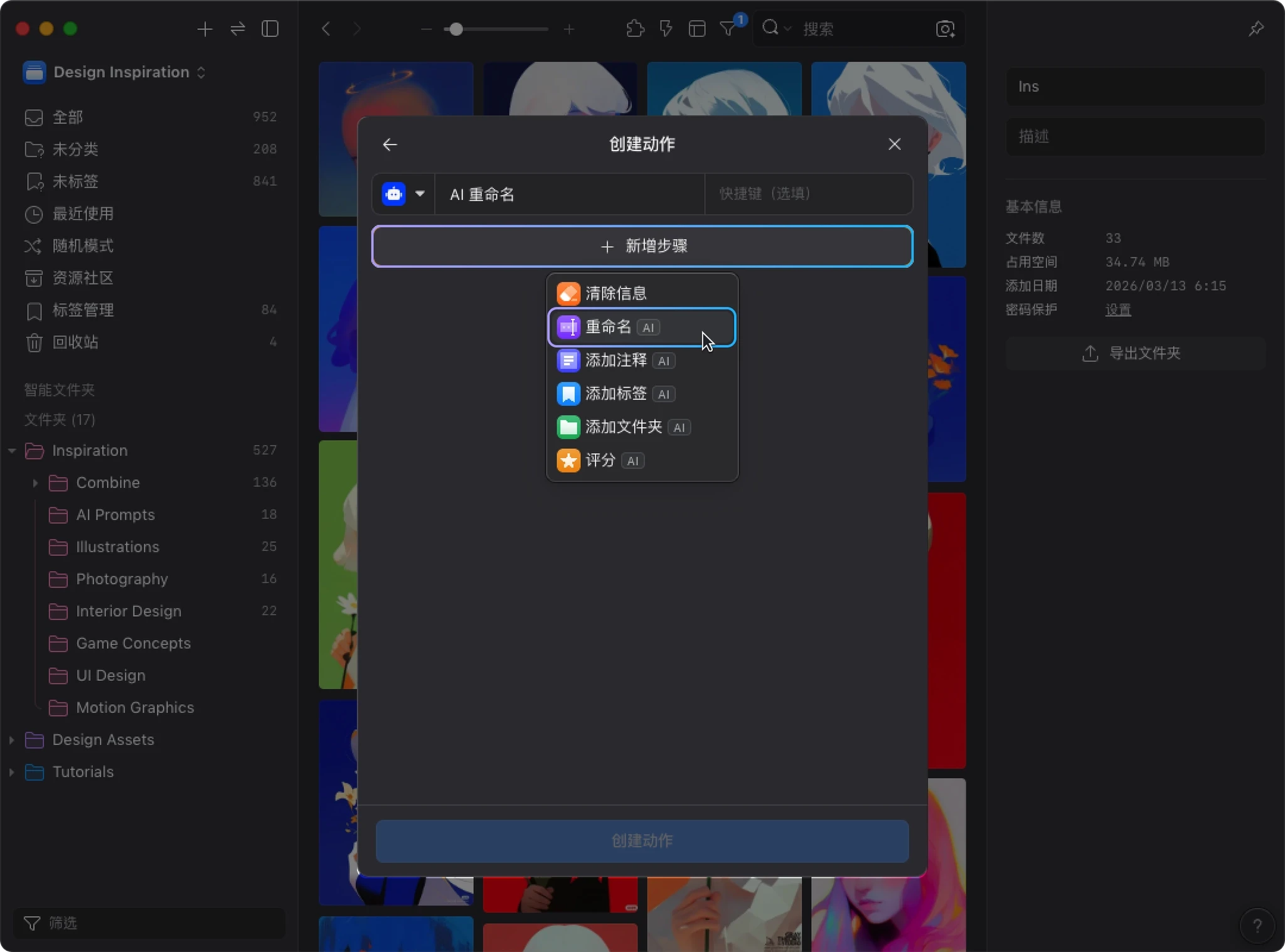
3. 先用默认配置完成创建
选择 重命名 后,会看到这个步骤的设置面板,包含:
- AI 模型
- 样式
- 额外上下文
- 自定义指令
- 输出语言
第一次先 保持默认值,不用急着调整。直接点击下方的 “创建动作” 即可。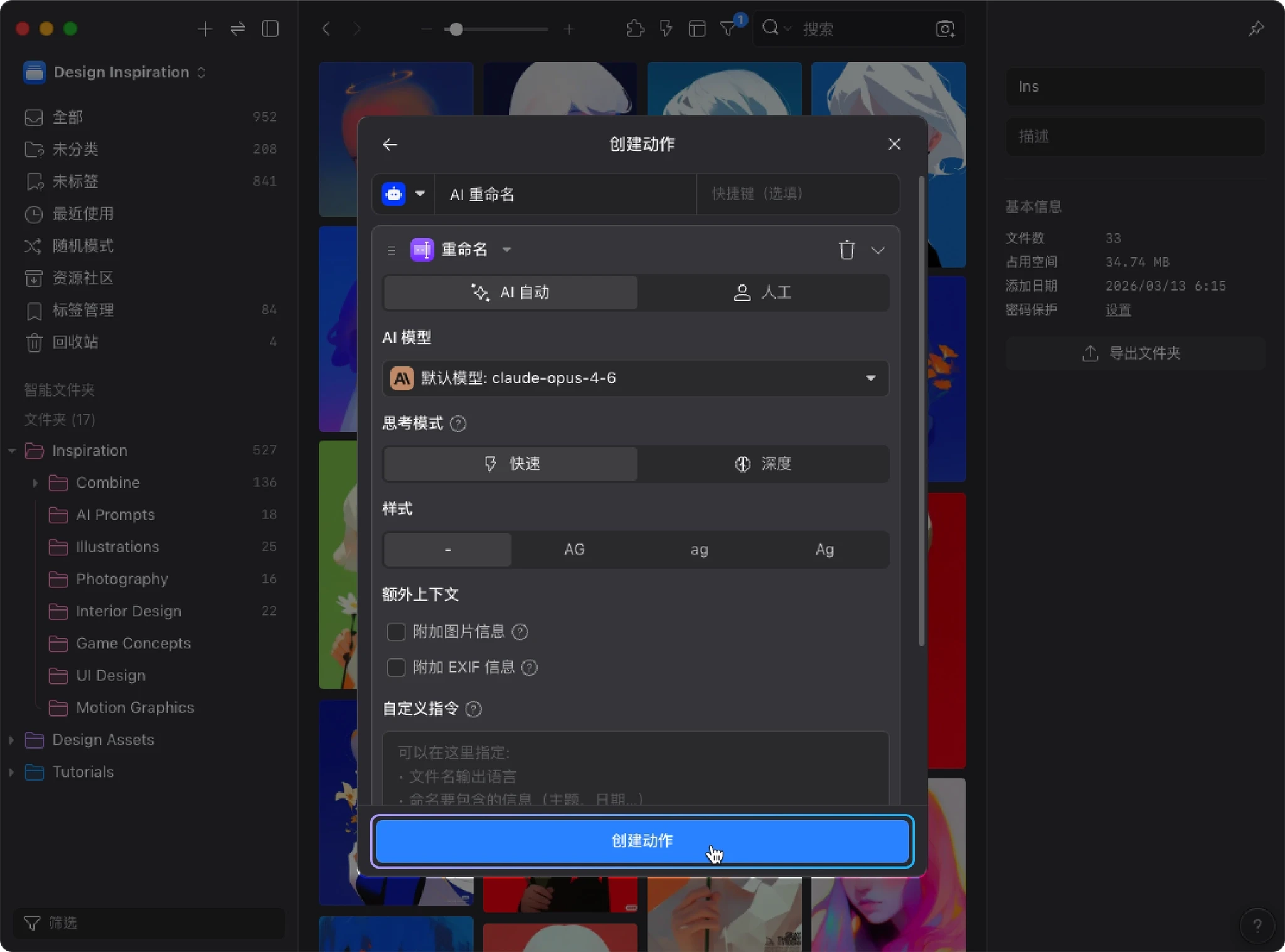
创建完成后,界面会回到动作列表,你就会看到刚刚创建的 AI 重命名 已经出现在列表中。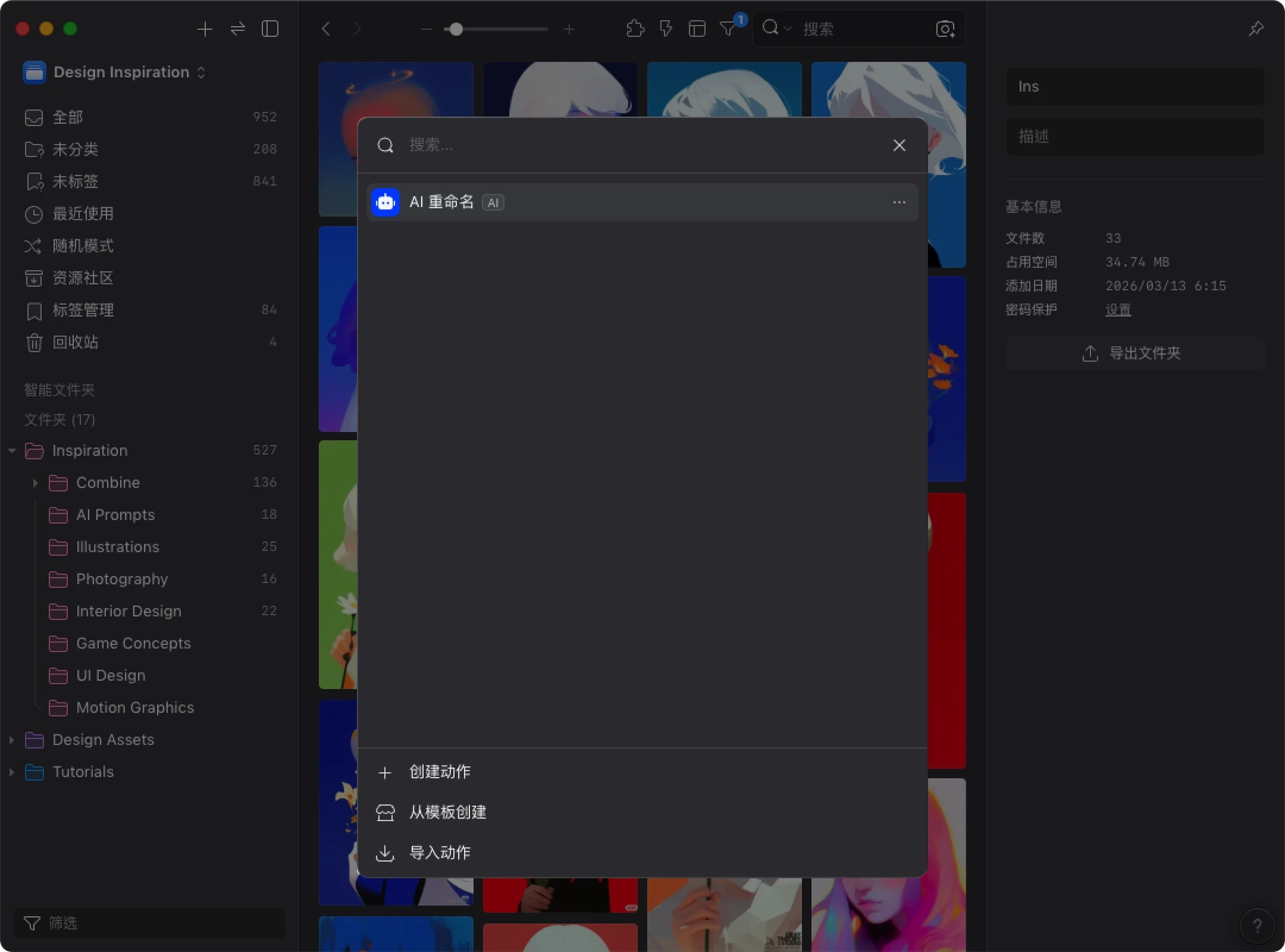
测试你的第一个动作
接下来拿几张图片实际跑一次。
选取图片并执行
- 关闭 AI 动作 窗口,回到 Eagle 的文件列表
- 选取 1~2 张想重命名的图片
- 打开右键菜单 “插件”,或直接按快捷键
P - 点击 “AI 动作”
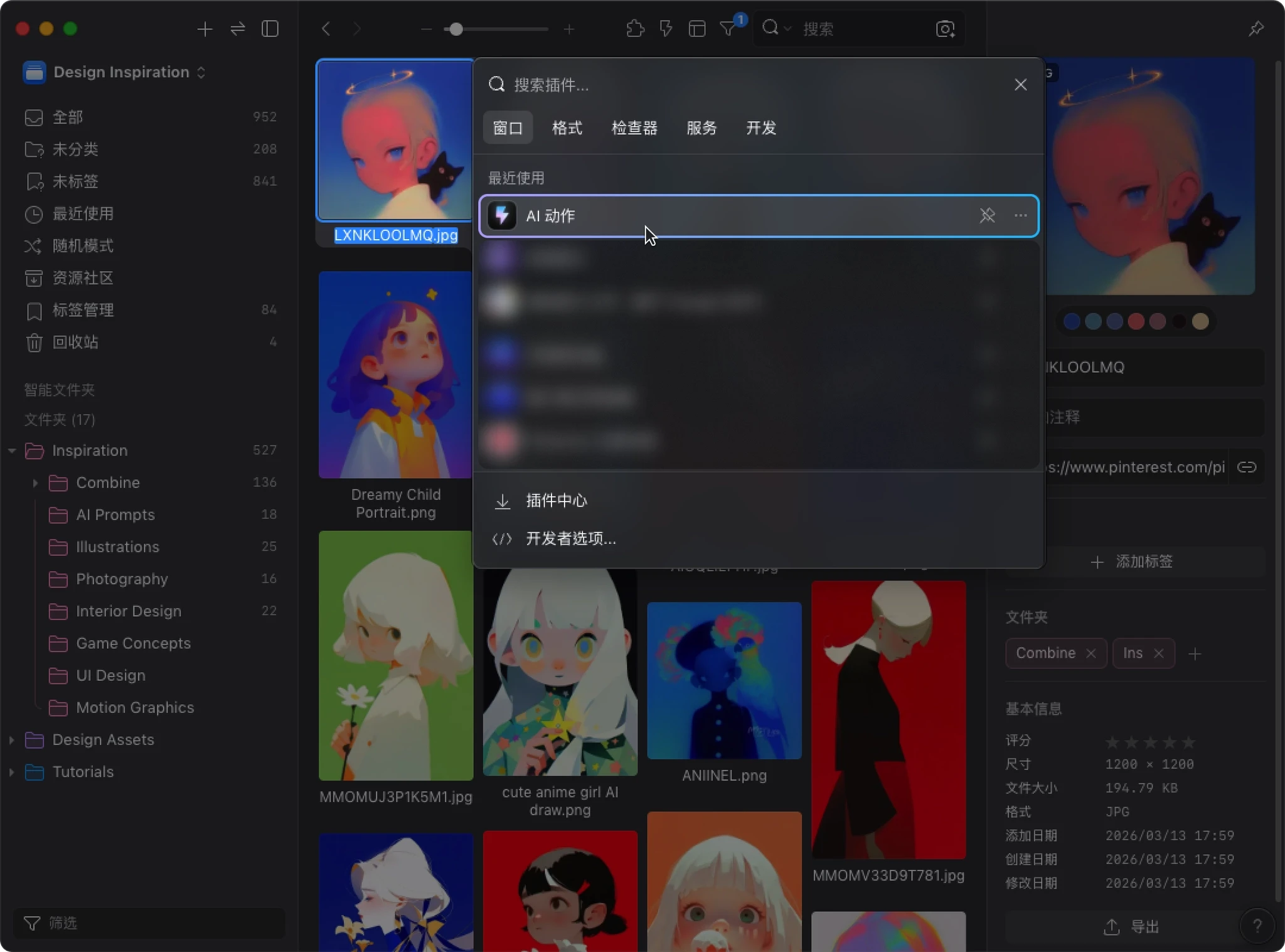
- 在动作列表中,点击刚才创建的 “AI 重命名”
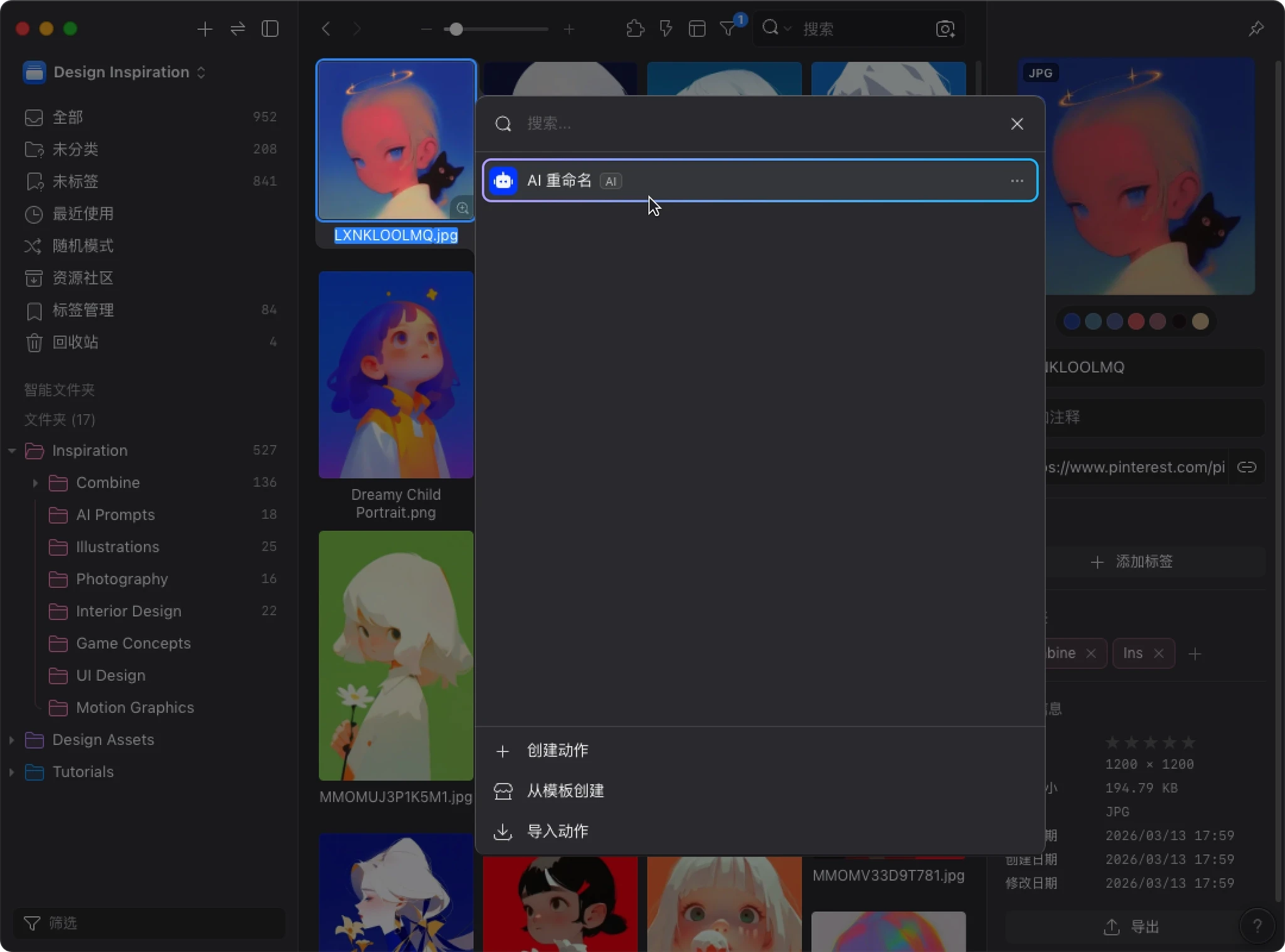
确认并执行
接着会进入 “执行动作” 的确认界面。这里会显示:
- 动作名称
- 选取的文件数量
- 即将执行的操作内容
如果这次有额外需求,你也可以在下方输入框中补充指示(选填)。确认无误后,点击 “执行动作” 开始处理。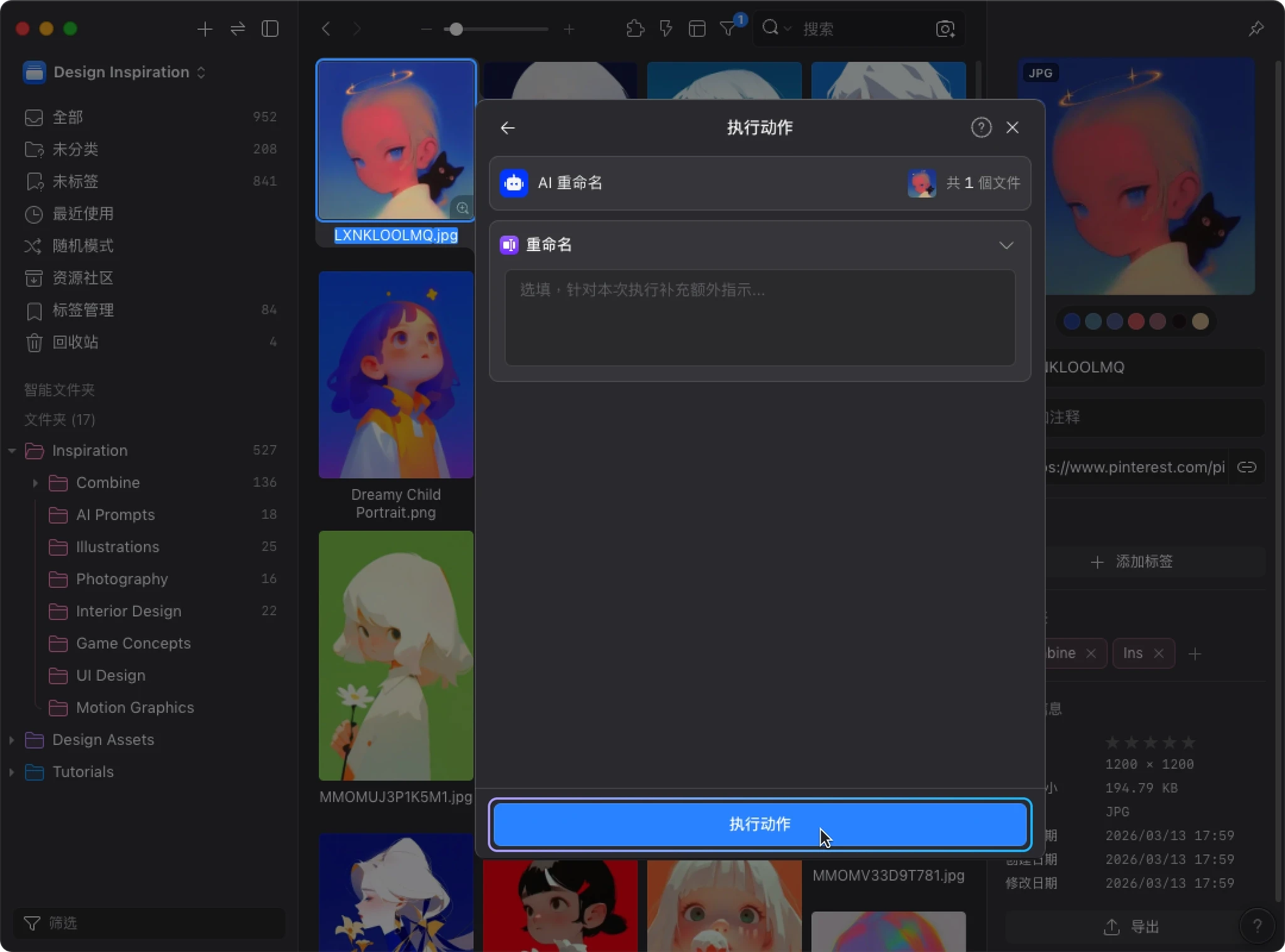
查看结果
执行过程中,你可以实时看到每个文件的处理状态。全部完成后,界面会显示 “已完成”,并列出每个文件的:
- 原始名称
- AI 重命名后的结果
点击 “确认” 关闭窗口,回到 Eagle 文件列表后,你就会看到刚才选取的图片已经完成重命名。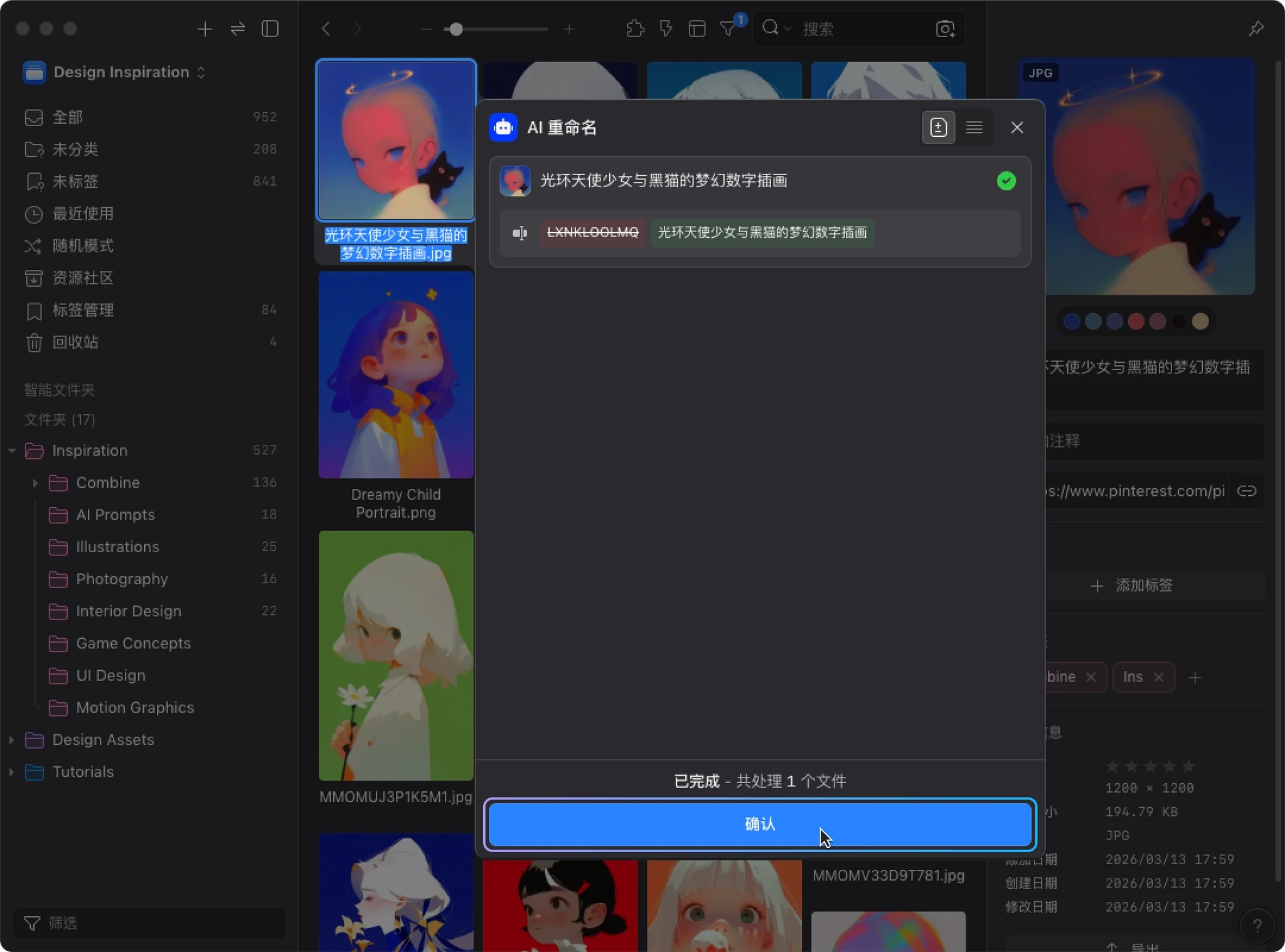
到这里,第一个 AI 动作 就完成了。
进一步定制:加入自定义指令
默认配置已经可以产出不错的结果。但如果你想进一步控制 AI 的输出方式,可以通过 自定义指令 来调整,让结果更贴合自己的工作习惯。
编辑动作
- 打开 AI 动作 插件
- 找到刚刚创建的动作
- 点击动作右侧的 “...”
- 在菜单中选择 “修改”
编写自定义指令
在编辑界面中,滚动到 “自定义指令” 字段,输入你的需求。
例如:请以简体中文命名,格式为“主体 - 风格特征”,长度控制在 15 字以内。
完成后,点击 “保存”。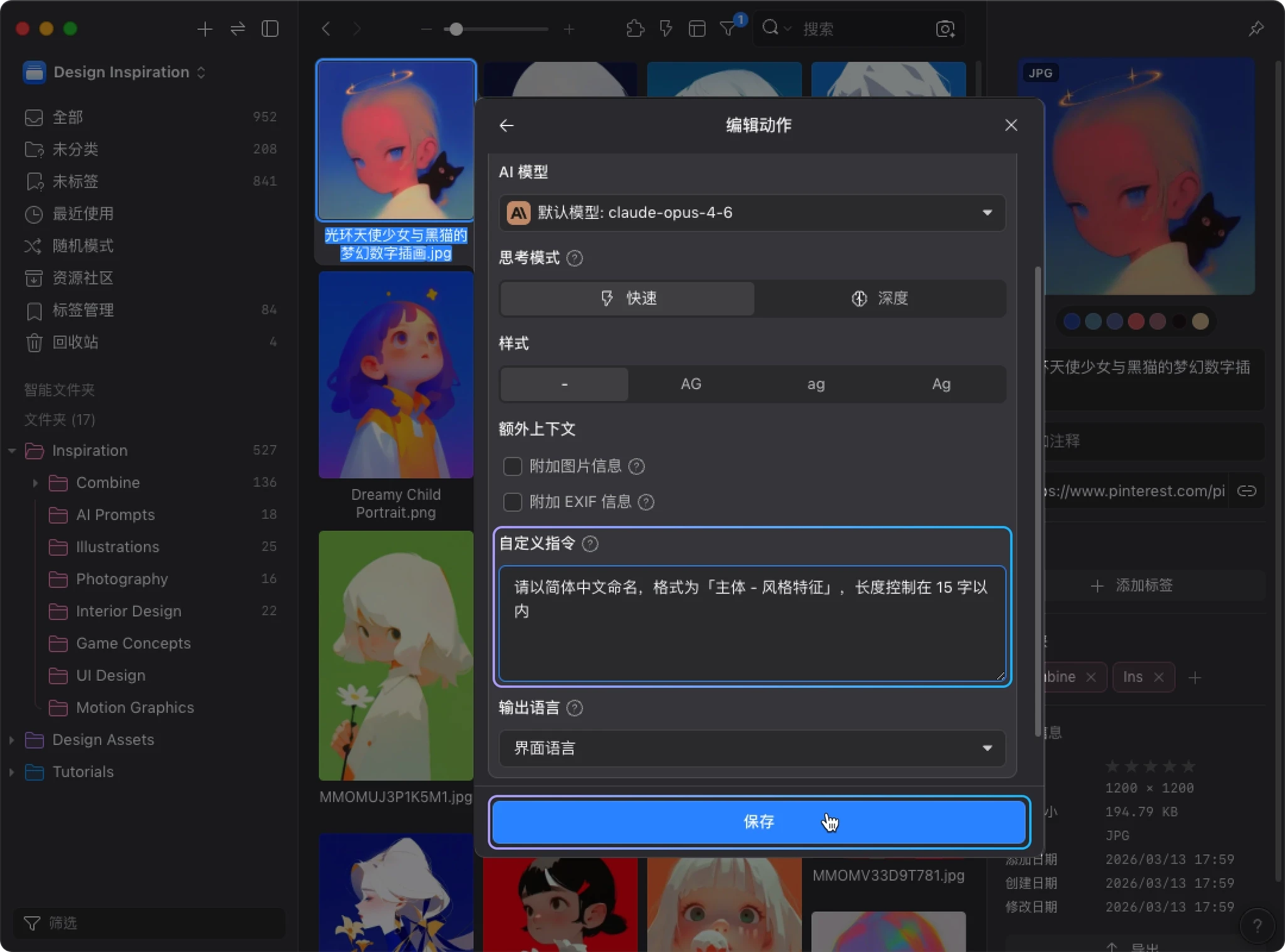
重新执行并比较结果
再次选取图片,重复前面的执行流程,观察这次结果与默认配置的差异。你会发现,AI 会明显按照你指定的格式、语言与表达方式产出更贴近需求的结果。
基本流程就是 创建 → 测试 → 微调指令 → 再测试,反复几次就能调出满意的效果。
使用模板快速创建动作
如果你不想从零开始,也可以直接使用模板快速创建。
- 在 AI 动作 窗口中,点击 “从模板创建”
- 浏览并选择适合你需求的模板
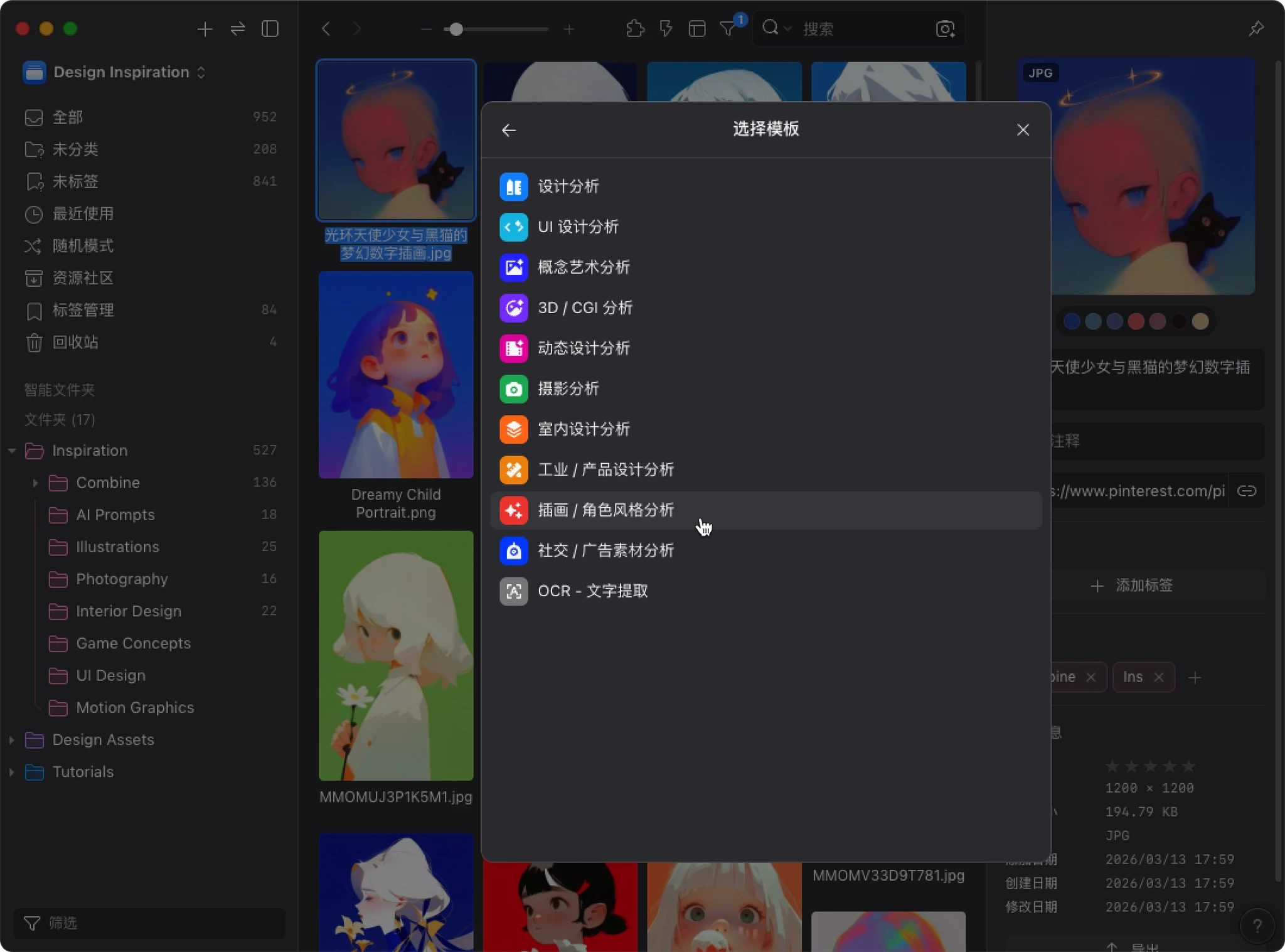
- 预览模板内容后,你可以直接创建,也可以先修改再创建
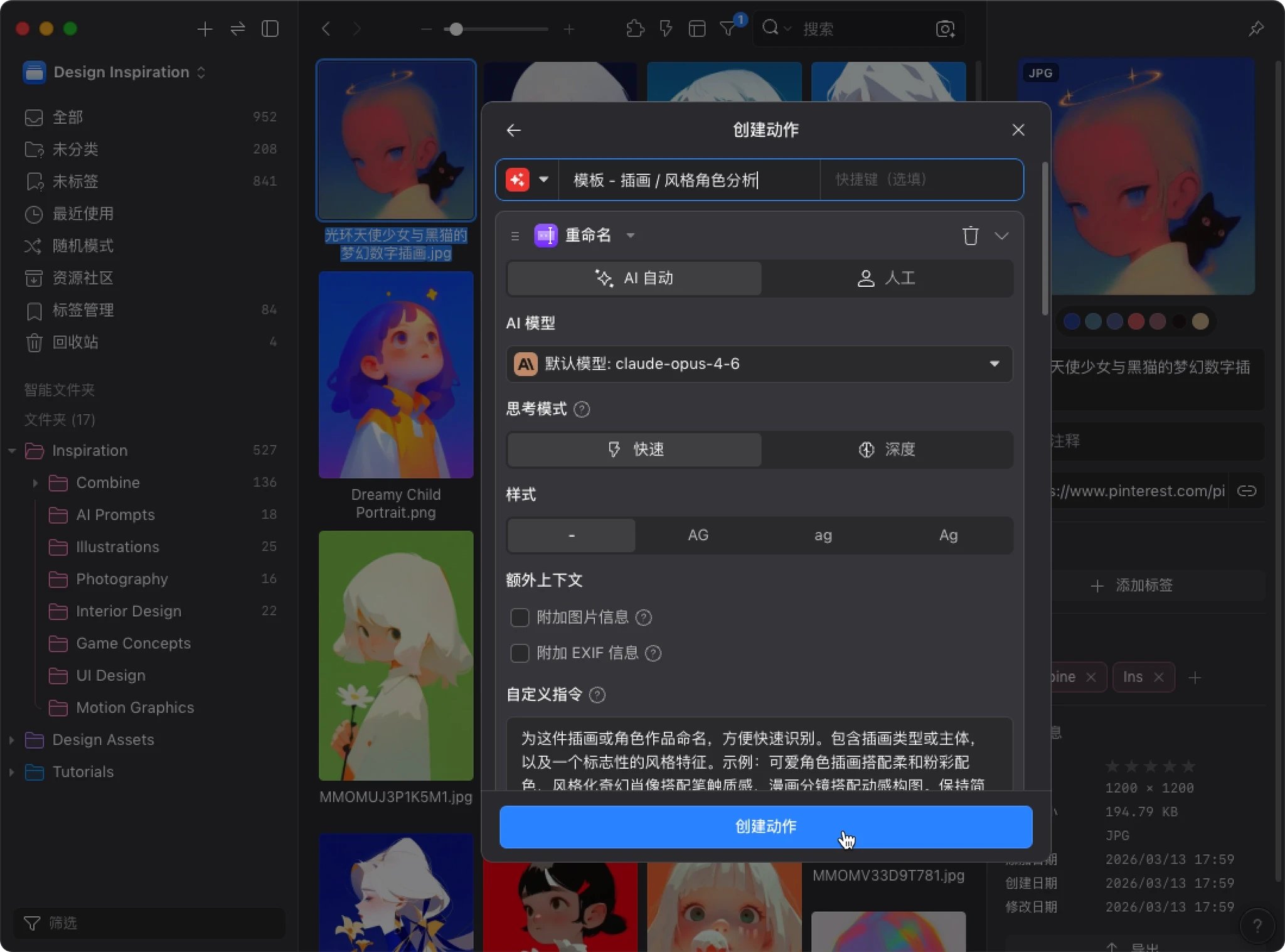
模板很适合作为起点。创建完成后,你依然可以通过 “修改” 持续调整,让它更符合自己的使用习惯。
新手建议:让 AI 动作 更快进入实用状态
先用最强模型确认效果
建议一开始先用较强的模型,例如 Claude Opus 4.6。如果强模型下结果仍不理想,问题多半出在提示词或配置方式,而不是模型能力,比较容易排查。
等确认效果成立后,再尝试切换到成本更低的模型,例如 Claude Sonnet 4.6 或 Haiku 4.5,看看是否仍能满足需求。
先小批量测试,再大批量执行
别一开始就拿大量图片跑。先挑 3~5 张不同类型的图片 测试,看看结果是否稳定。
调整时,也建议一次只改一个变量,例如:
- 只改提示词
- 只换模型
- 只改输出格式
这样比较容易知道是哪个配置真正影响了结果。
善用自定义指令
指令越具体,结果越稳定。建议写清楚:
- 使用语言
- 命名格式
- 长度限制
- 分析角度
- 希望保留或强调的信息
例如:
- 请以简体中文输出
- 请使用“主体 - 场景 - 风格”格式
- 请控制在 12 字内
- 请从 UI 设计角度描述图片
另外,尽量用正向指示。比如写 “请使用简体中文”,比 “不要使用繁体中文” 更稳定。
一个实用原则:你以后会怎么搜索图片,就让 AI 用同样的方式命名、描述与标记。
想了解更多提示词技巧,请参考 AI 动作 最佳实践指南。
推荐搭配:安装 AI 搜索,提升分类与标签准确度
如果你打算使用 AI 打标签 或 AI 文件夹 功能,建议先安装 AI 搜索 插件。
AI 搜索 会为资源库建立图片相似度索引。AI 动作 检测到这些数据后,就能参考视觉相似图片的已有整理结果来辅助判断,让分类和标签更准确、更贴近你原本的整理习惯。
安装方式
- 打开 “插件” → “插件中心”
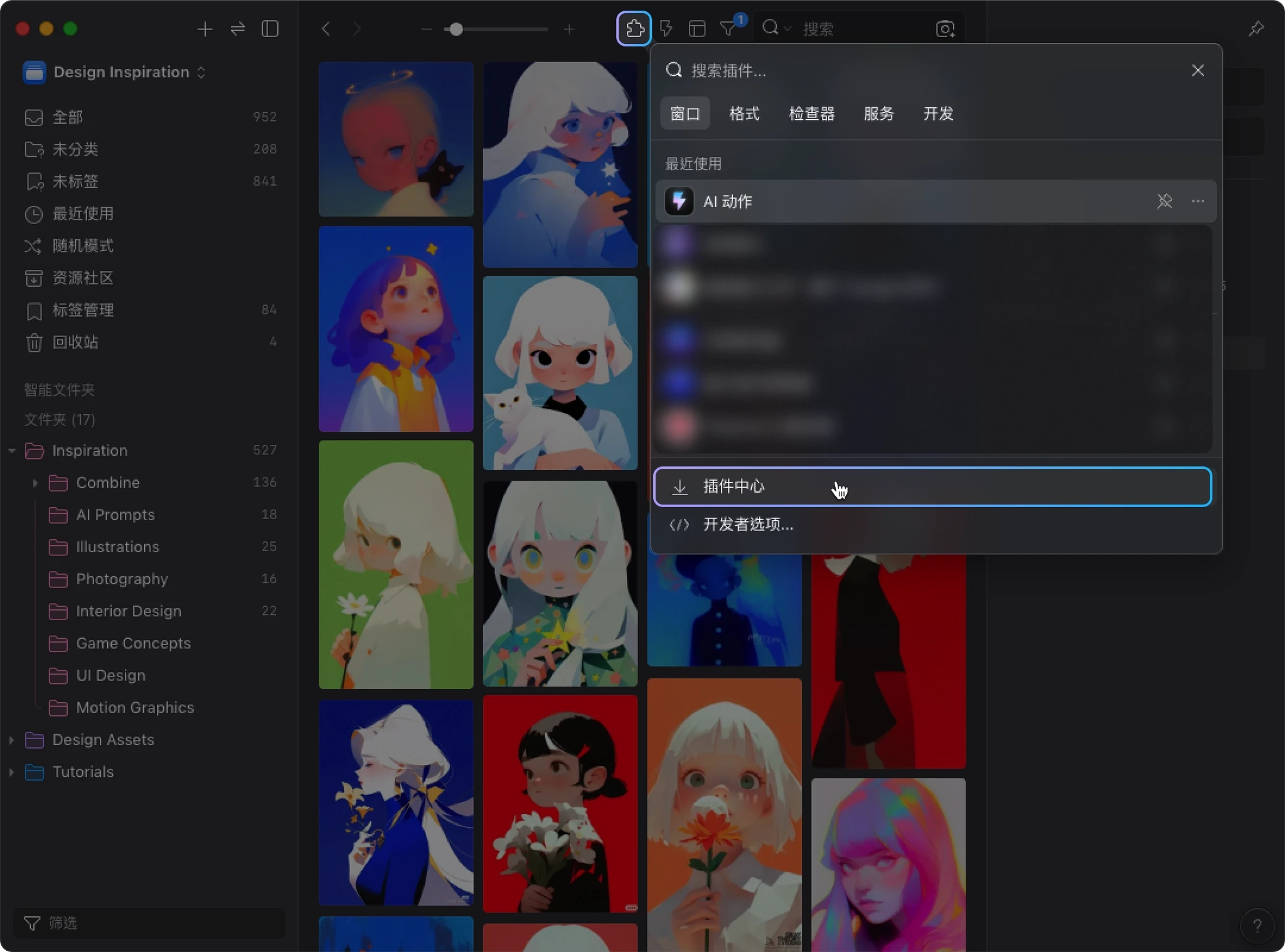
- 搜索 “AI 搜索” 并安装
下一步
到这里,你已经完成了:
- 安装并配置 AI 模型套件
- 安装 AI 动作 插件
- 创建第一个 AI 动作
- 执行图片重命名流程
- 通过 自定义指令 定制 AI 输出
- 了解如何用 模板 与 小批量测试 提升效率
除了重命名,AI 动作 还能做描述编写、自动分类、打标签、评分等。把不同步骤组合起来,配合自定义指令,就能搭出适合自己的图片整理流程。
💡 想进一步学会如何配置出效果更好的动作,请参考 AI 动作 最佳实践指南。
- [新增] 暂停执行时可一键「复原」已完成的变更,方便在误触 Action 时快速回退
- [新增] 模型选择器新增 OpenAI 兼容服务的图标
- [优化] 插件开启速度大幅提升,关闭后再次开启几乎无需等待(需 Eagle 4.0 Build 23 以上版本)
- [优化] 通过快捷键触发的纯手动 Action,将自动跳过确认页面直接执行
- [修复] 修复 Google Gemini 预览模型(如 gemini-3-flash-preview)不支持特定模型参数,导致 AI 标签、AI 文件夹功能无法正常执行的问题
首个发布版本